- 平铺矩阵乘法
- 这里一个线程控制了A的一行,B的一列; 但是是在for循环中分批次处理这一行和一列;因为要用共享内存
- for i=0的时候,处理第一个patch;注意看 tx是列,ty是行
if (i*BLOCK_SIZE + tx < numAColumns && row < numARows)
sharedM[ty][tx] = A[row*numAColumns + i * BLOCK_SIZE + tx];
else
sharedM[ty][tx] = 0.0;
if (i*BLOCK_SIZE + ty < numBRows && col < numBColumns)
sharedN[ty][tx] = B[(i*BLOCK_SIZE + ty)*numBColumns + col];
else
sharedN[ty][tx] = 0.0;
__syncthreads();
比如第一个C矩阵的block,i=0 遇到__syncthreads(),然后A和B的第一个patch填充到共享内存中,然后sharedM和sharedN相乘再相加,现在处理i=1,注意:现在还是第一个block,这里就是一个线程处理了A的一行,B的一列,现在处理的是这一行和一列的第二个patch,sharedM和sharedN被重新填充,这里是同一个block的共享内存
这里是以A的列就行划分patch,因为B的行和A的列相同
A[row*numAColumns + i * BLOCK_SIZE + tx] 取A对应patch的值,这里i代表的是A的列,就是在列上,第几个patch
B[(i*BLOCK_SIZE + ty)*numBColumns + col] 这里不同是因为i代表列B矩阵的行,行上第几个patch
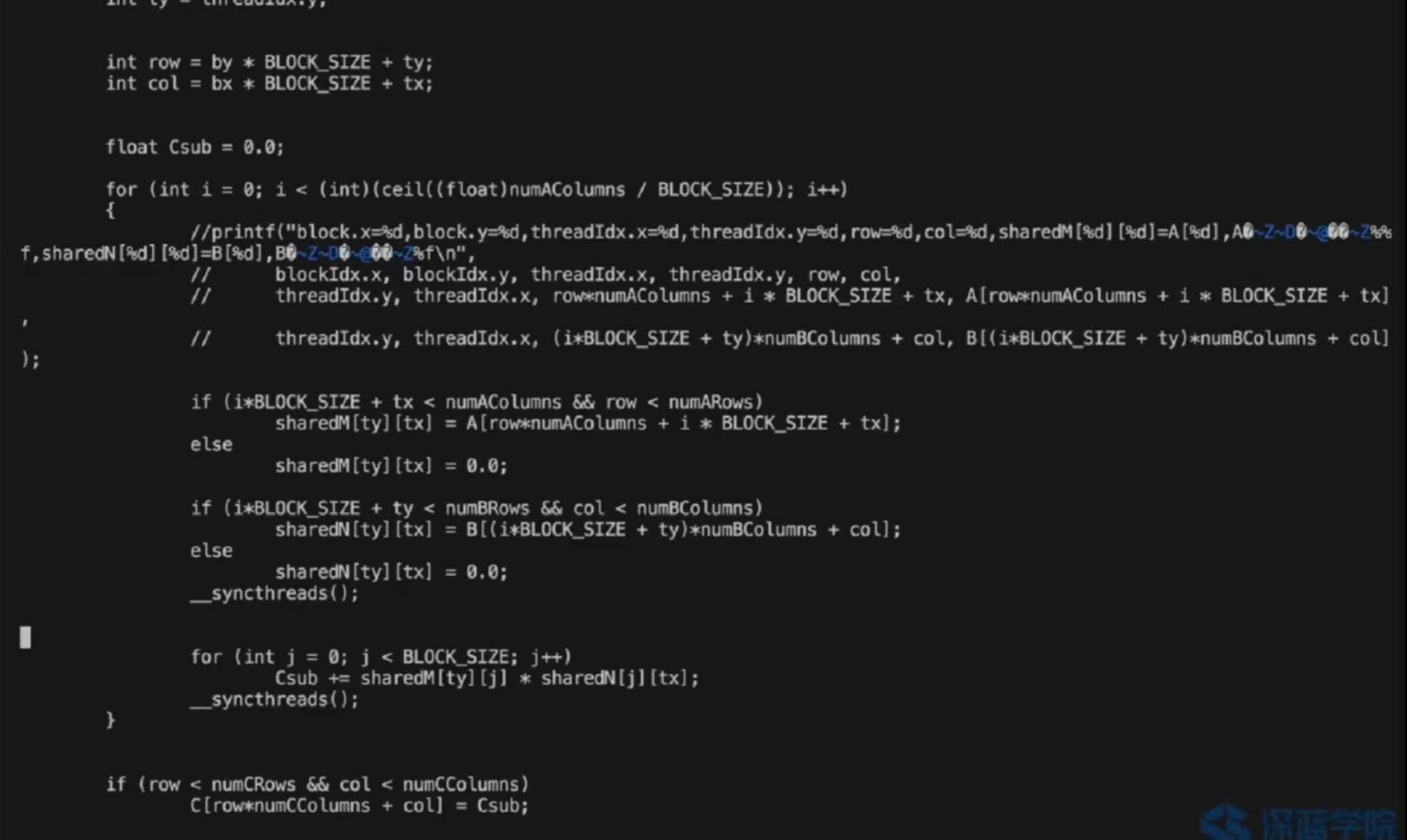
__global__ void matrixMultiplyShared(float *A, float *B, float *C,
int numARows, int numAColumns, int numBRows, int numBColumns, int numCRows, int numCColumns)
{
//@@ Insert code to implement matrix multiplication here
//@@ You have to use shared memory for this MP
__shared__ float sharedM[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float sharedN[BLOCK_SIZE][BLOCK_SIZE];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int row = by * BLOCK_SIZE + ty;
int col = bx * BLOCK_SIZE + tx;
float Csub = 0.0;
for (int i = 0; i < (int)(ceil((float)numAColumns / BLOCK_SIZE)); i++)
{
//printf("block.x=%d,block.y=%d,threadIdx.x=%d,threadIdx.y=%d,row=%d,col=%d,sharedM[%d][%d]=A[%d],A的值:%f,sharedN[%d][%d]=B[%d],B的值:%f\n",
// blockIdx.x, blockIdx.y, threadIdx.x, threadIdx.y, row, col,
// threadIdx.y, threadIdx.x, row*numAColumns + i * BLOCK_SIZE + tx, A[row*numAColumns + i * BLOCK_SIZE + tx],
// threadIdx.y, threadIdx.x, (i*BLOCK_SIZE + ty)*numBColumns + col, B[(i*BLOCK_SIZE + ty)*numBColumns + col]);
if (i*BLOCK_SIZE + tx < numAColumns && row < numARows)
sharedM[ty][tx] = A[row*numAColumns + i * BLOCK_SIZE + tx];
else
sharedM[ty][tx] = 0.0;
if (i*BLOCK_SIZE + ty < numBRows && col < numBColumns)
sharedN[ty][tx] = B[(i*BLOCK_SIZE + ty)*numBColumns + col];
else
sharedN[ty][tx] = 0.0;
__syncthreads();
for (int j = 0; j < BLOCK_SIZE; j++)
Csub += sharedM[ty][j] * sharedN[j][tx];
__syncthreads();
}
if (row < numCRows && col < numCColumns)
C[row*numCColumns + col] = Csub;
}

